「Metashape」のクラスタ構成での処理速度測定と傾向検証 (前編)
弊社でも引き合いをいただく事が多いMetashape (旧Photoscan)ですが、実はネットワークを組む事でクラスタ構成でも処理ができるソフトとなります。 以前にはPhotoScanでのGPUなどにおける処理速度の測定を行った事がありますが、ではクラスタ構成にした場合はどのような傾向になるのか…という事を検証してみました。

検証環境について
今回のテストに使用したクラスタ構成は以下の環境となります。
下記システムを4台用意しまして、3台は完全にクラスタノードとして動作させ、1台はMetashape用のServe兼ストレージサーバー兼ノードとしての検証となります。
クラスタシステム
| CPU | Intel Core i9 9900K (3.60GHz/TB5.0GHz, 8C/16T) |
| メモリ | 40GB |
| SSD | 1TB S-ATA |
| GPU | Geforce RTX 2080Ti × 1 |
| LAN | Onboard(1GbE) |
| OS | Microsoft Windows 10 Professional 64bit |
| Metashape | Ver 1.5.2.7838 |
また比較用としまして、1台単独で動作させた以下 仕様のマシンでのデータも参考として表示します。
比較用単体システム
| CPU | Intel Xeon W-2155 (3.30GHz/TB4.50GHz, 10C/20T) |
| メモリ | 256GB |
| SSD | 1TB M.2 |
| GPU | Geforce RTX 2080Ti × 2 |
| OS | Microsoft Windows 10 Professional 64bit |
| Metashape | Ver 1.5.2.7838 |
処理内容について
まずは、前回のテストでも利用したメーカー(Agisoft)が公開しているサンプルデータのDoll (Agisoft データダウンロードページ) で、①MatchPhotos ②AlignCameras ③BuildDepthMaps ④BuildDenseCloud ⑤BuildModel ⑥BuildUV ⑦BuildTexture の処理を実施しました。

※なお実施した処理は以下のパラメーターでの実施となります。
Aligen Photos : Highest
Build Dense Cloud : Ultra High
Build Mesh : Arbitray&Ultra High
Build Texture : Generic
処理結果について
以下がサーバーログで ①MatchPhotos~⑦BuildTexture までの一通りのトータル処理時間を計算した結果のグラフとなります。
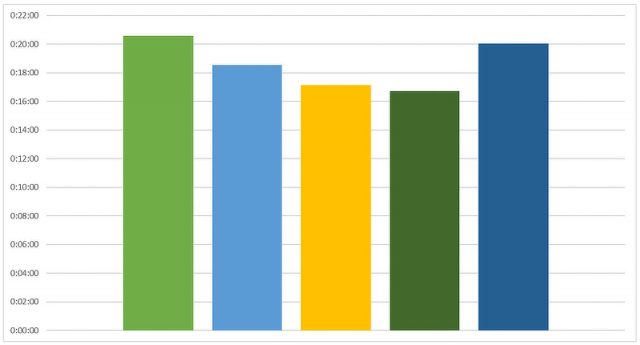
(Y軸=経過時間 : グラフが長いほど処理に時間がかかっている)
| クラスタ 1台 (RTX 2080Ti × 1) | 20分35秒 |
| クラスタ 2台 (RTX 2080Ti × 2) | 18分33秒 |
| クラスタ 3台 (RTX 2080Ti × 3) | 17分09秒 |
| クラスタ 3台 + サーバー兼用 1台 (RTX 2080Ti × 4) | 16分44秒 |
| 比較用単体システム (RTX 2080Ti × 2) | 20分03秒 |
クラスタ1台での処理速度が少し遅いのが目につきますが、クラスタの結果を見た限りでは 台数に応じて速度が速くなっています。ただ、GPUの枚数による差が少なく見え、果たしてクラスタ構成処理の効果があるのか…?という疑問がでてきます。
そこで、上記の処理時間についてログを確認し、Metashapeの各フェーズと思われる部分の実施結果ごとにデータをまとめてみました。この結果が以下のグラフとなります。
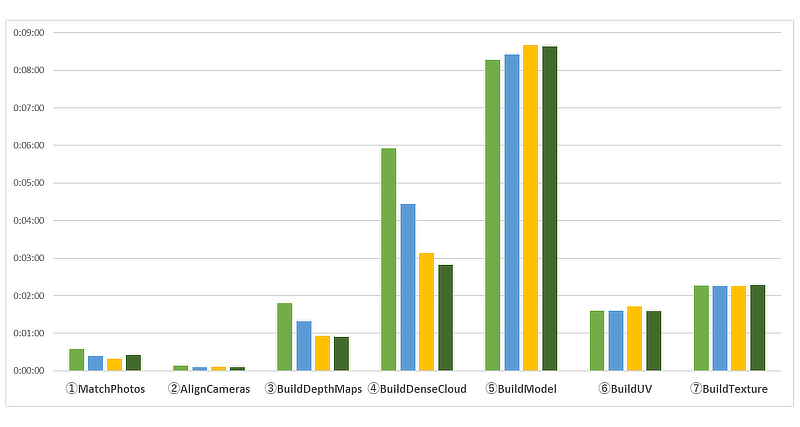
#単独システムの場合はログの出方が異なるため、上記のグラフには載せていません。
この分布から判断しますと前半の ①MatchPhotos~④BuildDenseCloud までの処理速度は、ある程度GPUやクラスタ台数のスケールを反映していますが、⑤BuildModel~⑦BuildTexture までについてはクラスタ台数によっての速度はあまり変わらないという結果になりました。
なお実際の検証時には計測中の負荷を確認していたのですが、⑤BuildModel~⑦BuildTexture のあたりの処理はすべて1台のクラスタノードでのみ実施されており、他のクラスタノードでは処理がされていないという状況が確認できました。
そしてもう一つ気になる点として、それぞれのフェーズにかかる時間にも注目する必要があります。
今回の計測では⑤BuildModel~⑦BuildTexture の時間が今回テストしたトータル処理時間の50%以上をしめています。
ここで最初に示した ①MatchPhotos~⑦BuildTexture までの一通りの処理時間を計算した結果のグラフを再度確認していただきたいのですが、本来であればGPUを2枚搭載したかなりのハイスペックであるはずの比較用単体システム(紺色のグラフ)ですが、実際には同じくGPU2枚のクラスタシステム2台(水色のグラフ)での処理よりも時間がかかっているという結果が出ていました。この原因を考えた場合に、比較用単体システムとクラスタシステムとの間でのGPU枚数以外のスペック差が、トータル処理時間の50%を占める⑤BuildModel~⑦BuildTexture の処理において、大きく影響しているのではないかと推察されました。
それを前提にスペック比較したところ、CPUにその要因があるように見受けられました。
改めて2つのCPUを比較して見てみます。
クラスタシステム
| CPU | Intel Core i9 9900K (3.60GHz/TB5.0GHz, 8C/16T) |
比較用単体システム
| CPU | Intel Xeon W-2155 (3.30GHz/TB4.50GHz, 10C/20T) |
クラスタ側のTB (Turbo boost)が 5.0GHzで動作するのに対して、単体システム側はTB 4.50GHzでの動作となっています。つまり⑤BuildModel~⑦BuildTexture については、CPUの単独クロックが処理速度に対して特に有効となるという推測が成り立ちます。
では⑤BuildModel~⑦BuildTextureを、今回の例より十分に多いコア数優先の処理 にした場合にどうなるのか…?という疑問が発生します。
この疑問については近日公開いたします”「Metashape」のクラスタ構成での処理速度測定と傾向検証 (後編)“でのオルソ画像処理の一連のバッチ処理の検証結果と共にご報告します。
| ■ 2019年6月28日追記 : 後編記事を公開しました! |
| ■ 2019年7月11日追記 : こちらの検証に利用したクラスタノードPCを事例として公開しました |




