DeepLabCutによる動画学習を複数のGPUで動かしてみた

|
[目次] 検証方法 |
弊社で提供しているオーダーメイドPC製作サービス TEGSYSでは、お客さまのご要望に合わせ、最適なスペックのPCをご提案しております。
今回は、これまでに多数の提案実績があるDeepLabCut用マシンについて、GPUの違いによる学習の処理速度差を比較してみました。
検証に用いたGPUはRTX 4090、RTX Ada 6000、RTX A6000 の3種類です。
|
動物の行動を分析するためのオープンソースのディープラーニングツール。動画から動物の特定の身体部位を識別しマーカーレスでの追跡が可能で、精度の高い動きの分析を提供する。 |

検証方法
比較するGPUの仕様
本記事の検証で使用したGPUのスペックは下記のとおりです。
| GPU architecture | NVIDIA GeForce RTX 4090 | NVIDIA RTX A6000 | NVIDIA RTX 6000 Ada |
| CUDA core | 16384コア |
10752コア |
18176コア |
| Tensor core | 512コア | 336コア | 568コア |
| RT core | 128コア | 84コア | 142コア |
| memory size | 24 GB GDDR6X | 48 GB GDDR6 | 48 GB GDDR6 |
| memory bandwidth | Up to 1008GB/s | Up to 768GB/s | Up to 960GB/s |
| Maximum power consumption | 450W | 300W | 300W |
コンピュータ仕様
GPU以外のハードウェア仕様は変更せずパフォーマンスを測定しました。
CPU等のスペックは下記のとおりです。
| Chipset | Intel W790 |
| CPU | Intel Xeon w7-2465X (3.10GHz 16コア 32スレッド) |
| RAM | 合計64GB (DDR5-4800 ECC Registered 16GB x4) |
| Storage | 1.92TB SSD S-ATA |
ソフトウェア環境
検証で使用したOS環境と機械学習関連ソフトウェアは以下の通りです。
| OS | Windows 11 |
| 機械学習フレームワークおよびそのサポートツール | Tensorflow 2.9.1 CUDA Toolkit 11.2 cuDNN 8.1.1 Anaconda3 |
学習・動画分析の実行対象
本検証では、学習・動画分析の実行対象として DeepLabCutがサンプル提供しているネズミの動画 を使用しました。
| サンプル動画の概要 | ||
 |
解像度 | 640 x 480 |
| フレームレート | 30fps | |
| 長さ | 1分17秒 | |
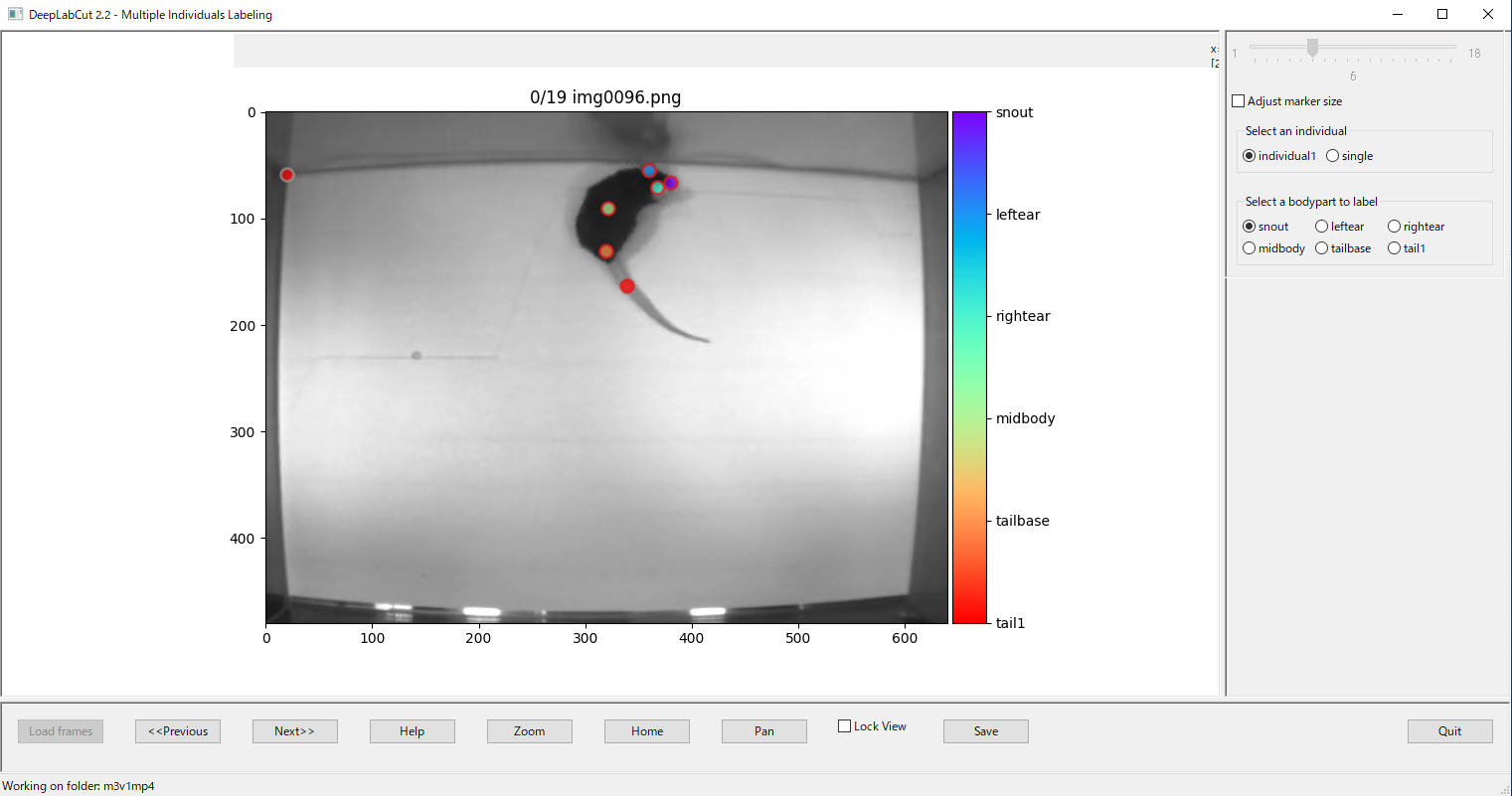
動画からデフォルト設定で19枚の画像を抜き出し、それぞれに下記のラベル情報を手動で付与します (合計7点)
| DeepLabCutでのラベル情報設定画面 | ||
 |
||
| ラベル付与対象 | 生物 | snout (鼻) 、leftear (左耳) 、rightear (右耳) 、midbody (胴体の中央) tailbase (尾の付け根) 、tail1 (尾の中央あたり) |
| 環境 | cornerofbox (移動フィールドの左上の角) | |
学習処理 (Train処理) の実行条件・パラメータ
本検証は、以下の実行条件・パラメータで実施しました。
| Network: resnet_50 Augumentation Method: imgaug Maximum Iterations: 200,000 |
学習の反復回数の値を大きくすると、学習にかかる時間が増えるかわりに学習結果の精度が向上します。
今回は最大反復回数を200,000回に設定して検証しました。
| DeepLabCut – Step 4.Create training datasetの画面 | DeepLabCut – Step 5.Train networkの画面 |
 |
 |
測定内容と結果
測定内容
本検証では、学習処理実施時の各GPUについて、以下の5項目を測定しました。
|
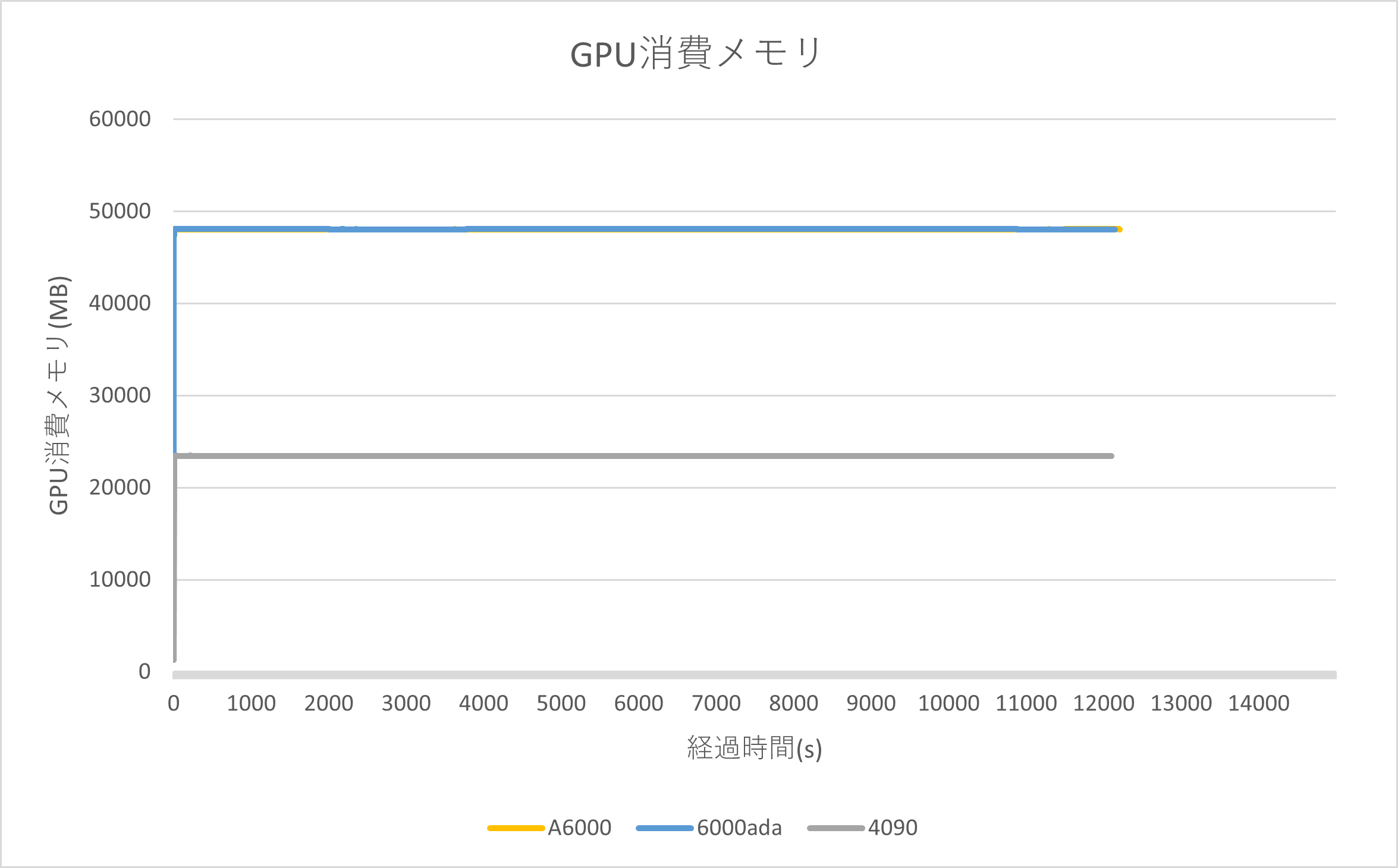
測定結果
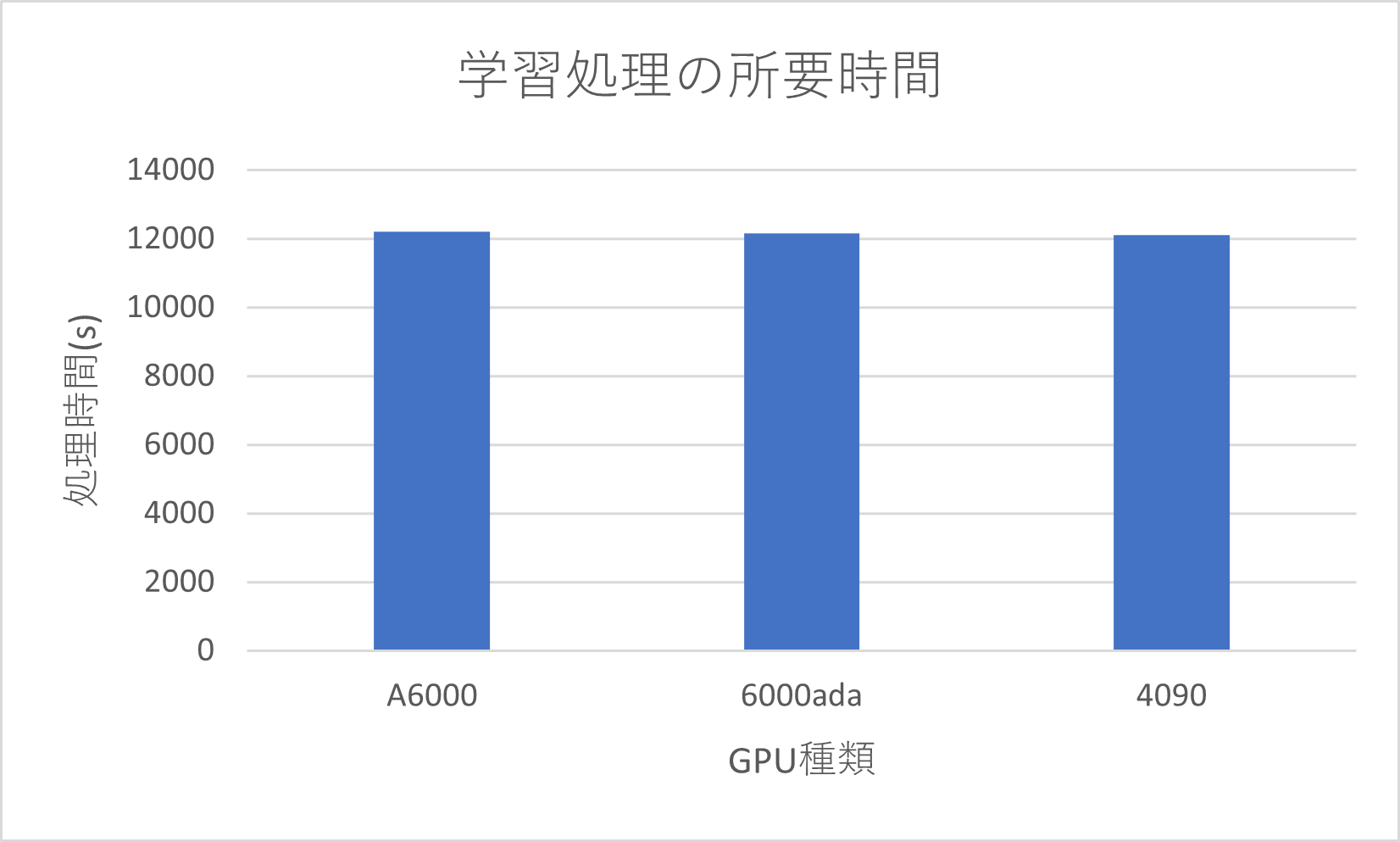
| GPU消費メモリ | 学習処理の所要時間 | ||||||||||
 |
 |
||||||||||
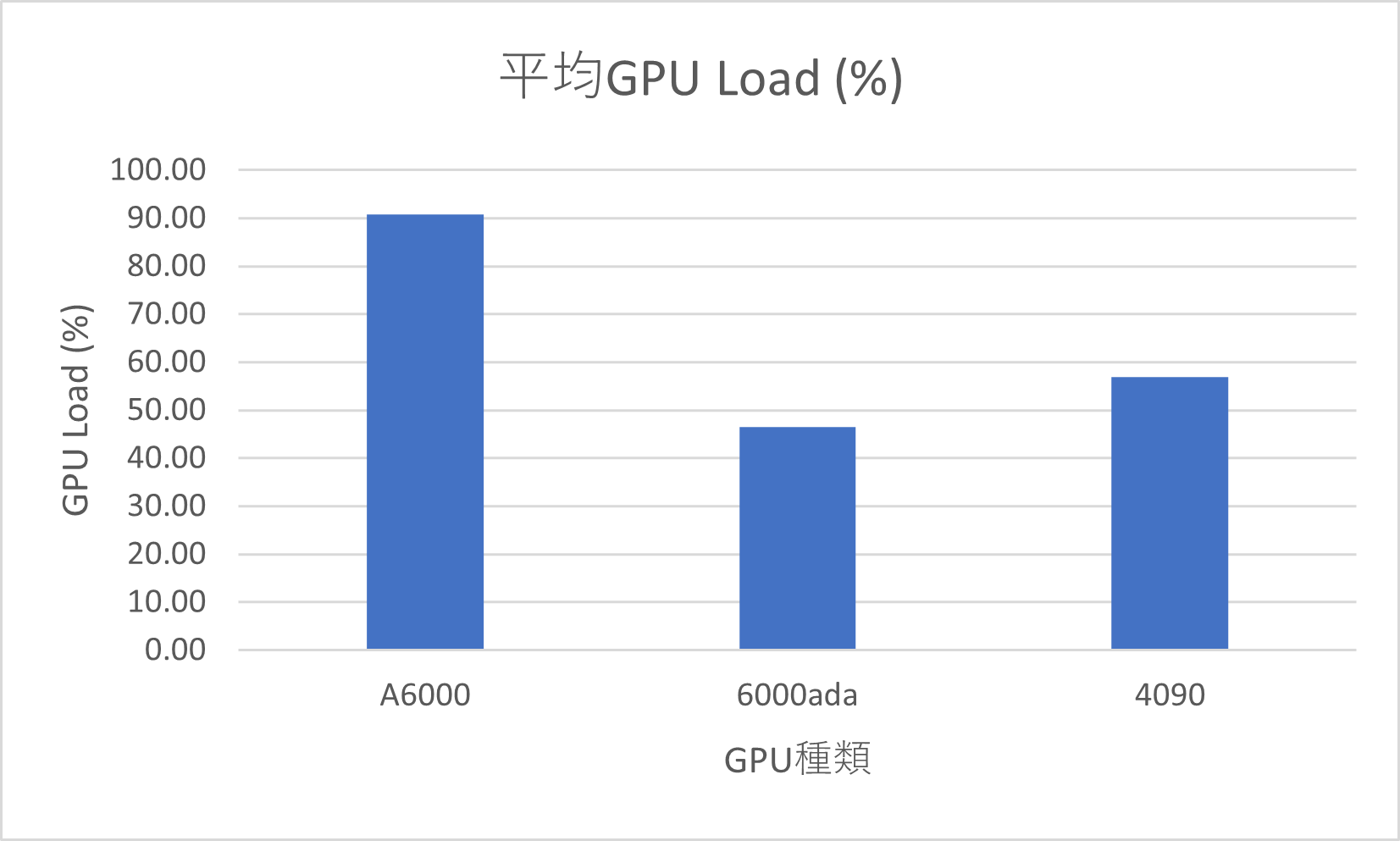
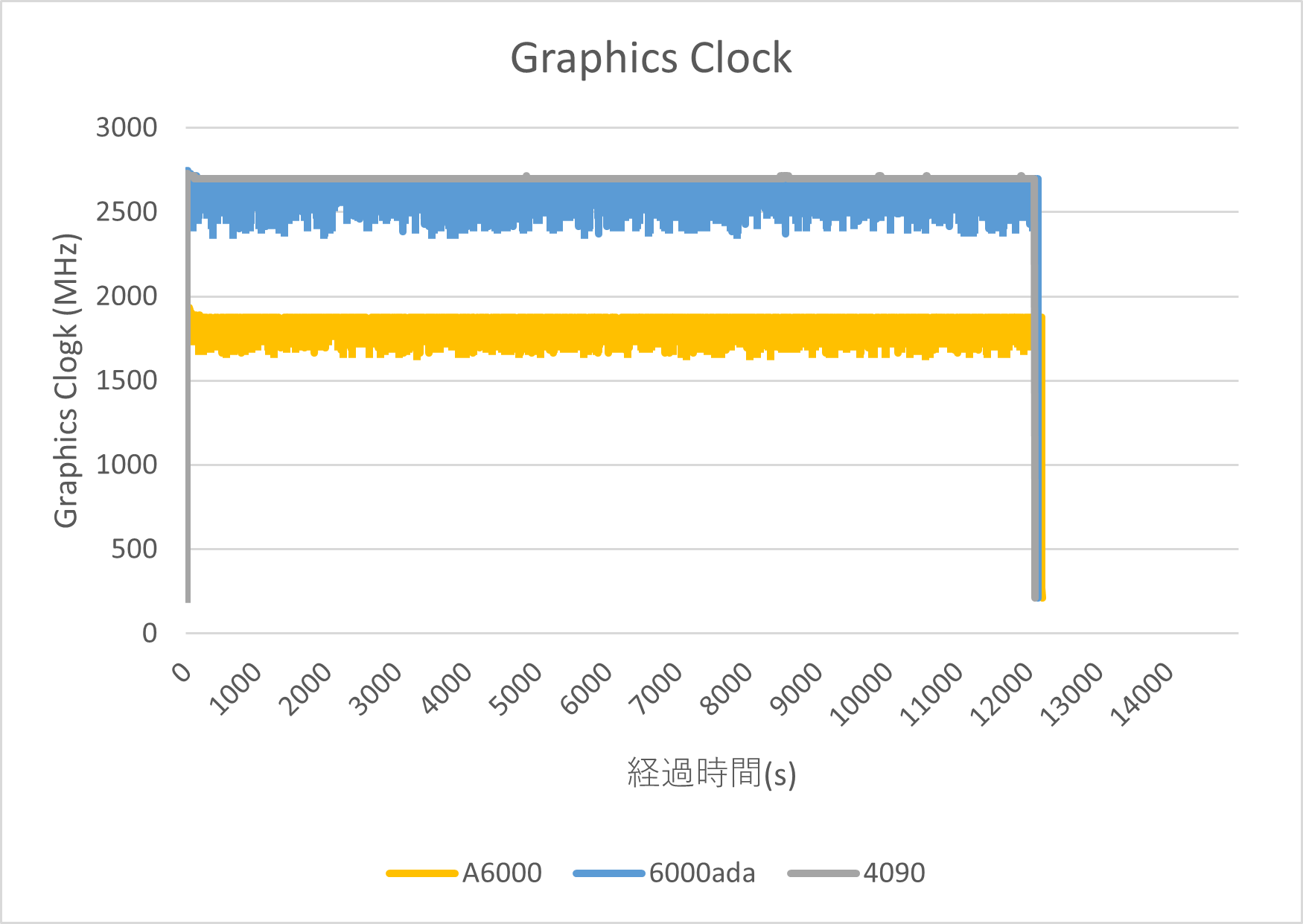
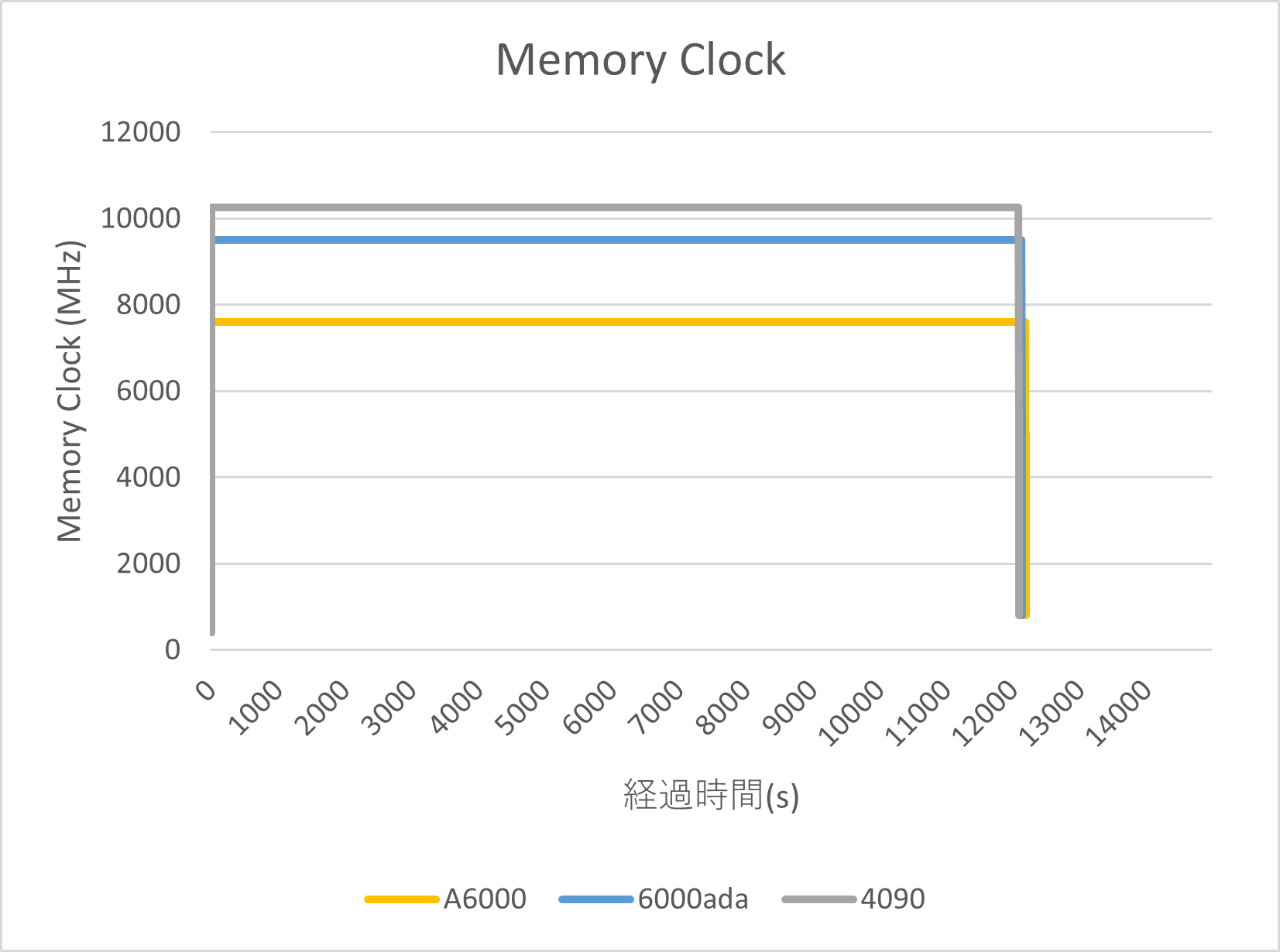
| GPUの使用率 | GPUクロック (GraphicsClock) | GPUクロック (MemoryClock) | |||||||||
 |
 |
 |
|||||||||
考察
| 処理時間 | 今回のGPU 3種では学習時間に大きな差は見られない |
| GPUメモリの消費 | 当該ソフトウェアは処理開始直後に全GPUメモリ領域を確保すると考えられる |
| メモリサイズと動作速度 | 影響は確認できず |
| GPU Load | RTX4090と6000adaはGPUリソースを活用しきれていない状態を確認 ※ソフトウェアやライブラリのVerや学習時の実行条件などが影響する可能性あり |
処理時間について、3種類のGPU間では学習時間に大きな差がみられませんでした。
GPUメモリの消費についてはグラフより当該ソフトウェアは処理開始直後にすべてのGPUメモリ領域を確保する動作と思われますが、RTX 4090 (24GB) と A6000や 6000ada (48GB) 間では、GPUメモリサイズによる動作速度への影響は今回の実行条件では確認できませんでした。一方で GPU Load では、RTX 4090 と、特に6000ada はGPUリソースを活用しきれていない状態が見受けられます。 可能性としては、Tensorflow 2.9.1、CUDA Toolkit 11.2、cuDNN 8.1.1 を使用いたしましたが、インストールするソフトウェアやライブラリのバージョンが古いものがあったことが原因として考えられます。ソフトウェアを最新のものや適切なバージョンに調整することによって4090 や 6000Ada のリソース活用状況が改善する可能性がございます。
その他の要素として、 DeepLabCut は学習ネットワークとしてresnet_50以外にも resnet_101、moobilenet、efficientnet といったモデルが選択可能で、学習時の実行条件によっても結果が変わる可能性が考えられます。
今回の結果を踏まえ、次回の記事ではインストールするソフトウェアのバージョンや実行条件の調整、その他さらに旧世代のGPUを用いた追加の評価を行う予定です。
なお、ご参考までに、学習をもとに動画を分析しましたところ、下記の動画の通りラベル付けができました。
おわりに
弊社では、AI・ディープラーニング用途向けのPCやワークステーション以外でも、お客さま個別のご要望に合わせ、最適なスペックのPCをご提案しております。
これまでのご提案実績や検証結果等のノウハウをもとにベストな提案を目指しておりますので、PC導入はお気軽にご相談ください。


|
DeepLearning環境における最適なGPU選びのご相談はお気軽に! 研究用・産業用PCの製作・販売サービス TEGSYS – テグシス
|





