OSインストール環境の違いによるAIの実行Performance比較 (Linux、Docker、WSL2)

多くの計算リソースが必要なAIや機械学習では、計算処理のパフォーマンスと効率性は重要なテーマです。
本記事では、AIタスクの推論処理にかかる時間を、異なる実行条件 (主にOSのインストール環境の観点) のもとで比較しました。

推論処理の実行条件
OSインストール環境
比較検証に使用したOSのインストール環境は以下の3種です。
| ネイティブLinux (Ubuntu) | 一般的な方法で、マシンに直接Linux (Ubuntu) をインストールした環境 |
| Docker on Linux (Ubuntu) | Dockerで構築した仮想空間にLinux (Ubuntu) をインストールした環境 |
| Windows WSL2 | Windows Subsystem for LinuxによるWindows上でのLinux実行環境 |
コンピュータ仕様
GPU以外のハードウェア仕様は変更せずパフォーマンスを測定しました。
CPU等のスペックは下記のとおりです。
| Chipset | Intel W790 |
| CPU | Intel Xeon w7-2465X (3.10GHz 16コア 32スレッド) |
| RAM | 合計64GB (DDR5-4800 ECC Registered 16GB x4) |
| Storage | 1.92TB SSD S-ATA |
上記スペックを共通として、3種のGPU (RTX4090、RTX 6000ADA、RTX6000) での計算時間を比較しました。
テストしたモデル
以下の3つのモデルを使い、OSインストール環境・GPUの違いによる処理速度を比較しました。
| ResNet-50 | |
| 50層の畳み込みニューラルネットワーク、画像認識モデルで主に利用される | |
| タイプ:畳み込みニューラルネットワーク (CNN) | タスク:画像分類 |
| BERT | |
| 自然言語の文脈や関係性を処理するために主に利用される | |
| タイプ:トランスベースのモデル | タスク:自然言語処理 (NLP) |
| GPT-2 | |
| 大規模言語モデルで、テキスト生成、翻訳、質問応答など、さまざまな自然言語処理タスクを実行できる | |
| タイプ:トランスベースのモデル | タスク:テキストと自然言語処理 (NLP) |
評価方法
各AIモデルの推論タスクを異なる環境とバッチサイズごとに10回計算を繰り返し、バッチあたりの平均時間を測定しました。評価スクリプトの概要は下記の通りです。
|
結果
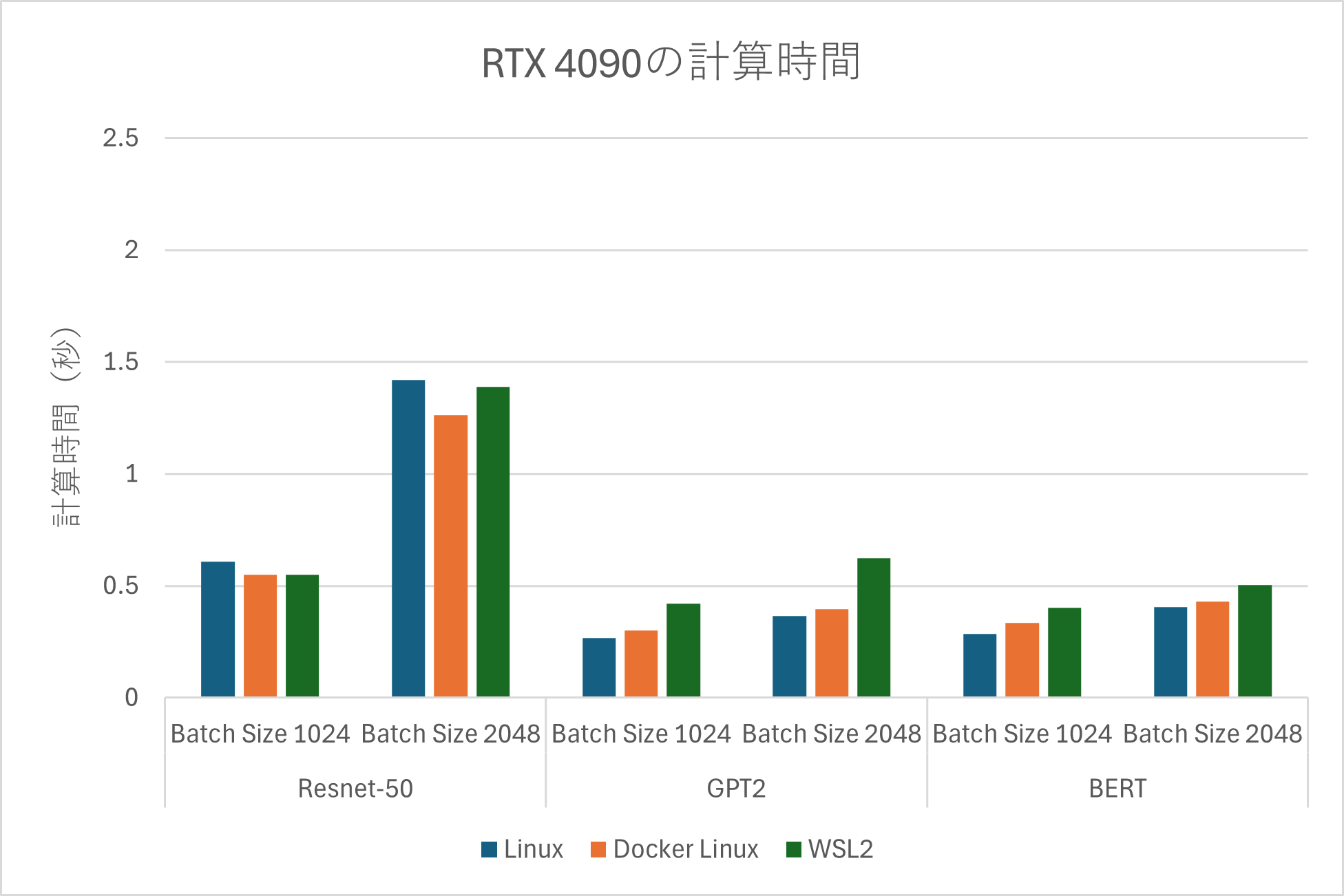
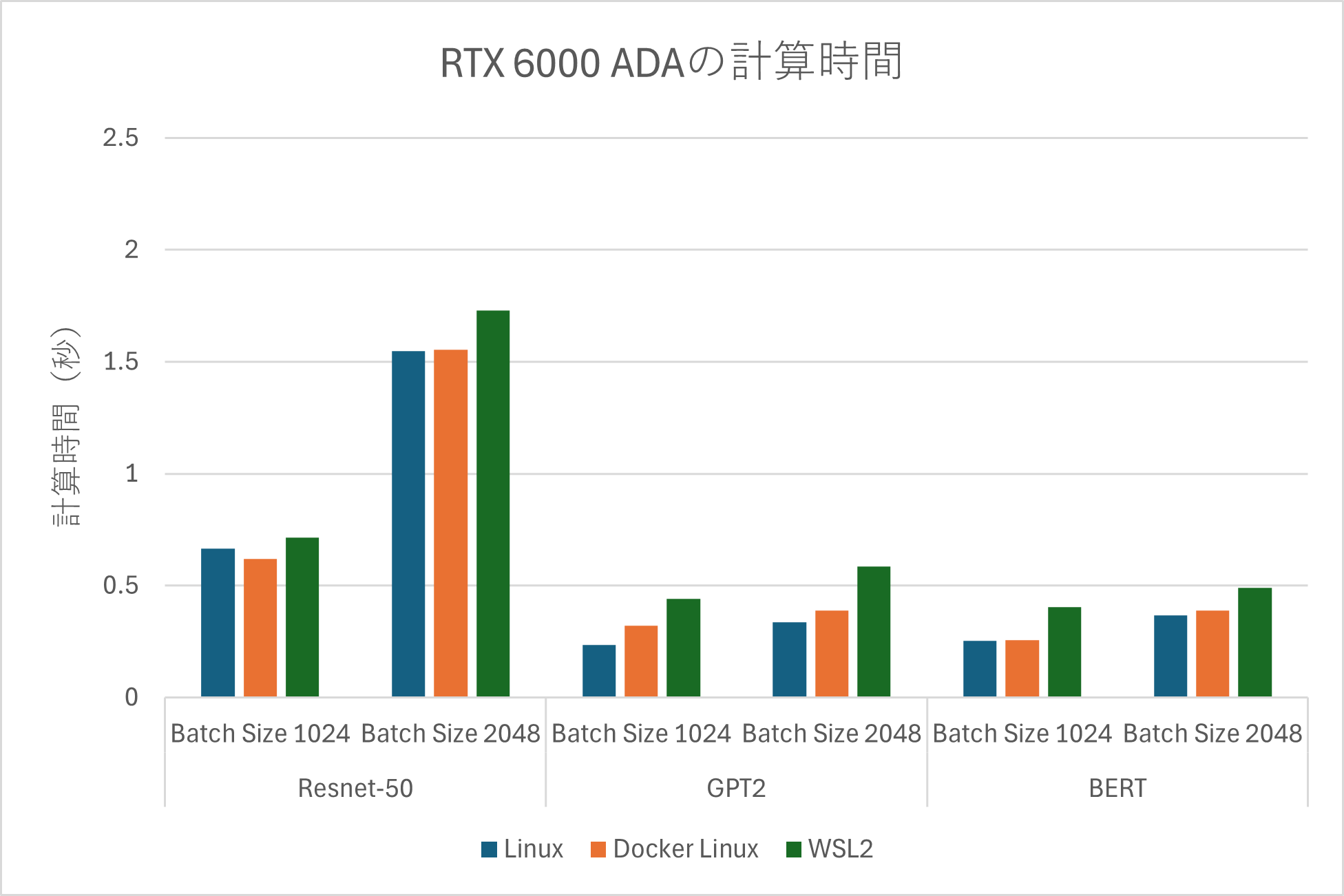
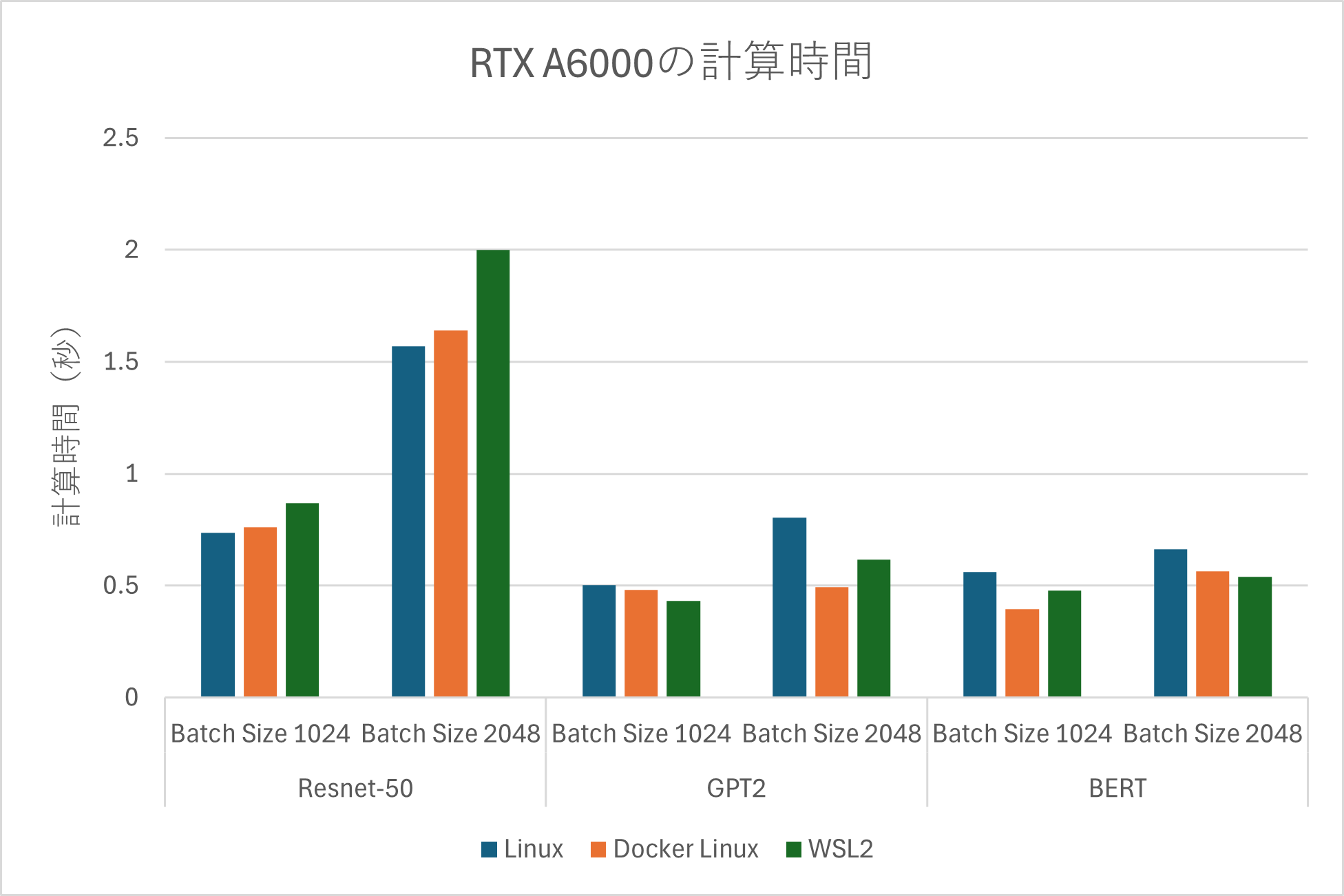
GPU毎の計算時間
| RTX4090 | RTX6000ADA | RTX6000 |
 |
 |
 |
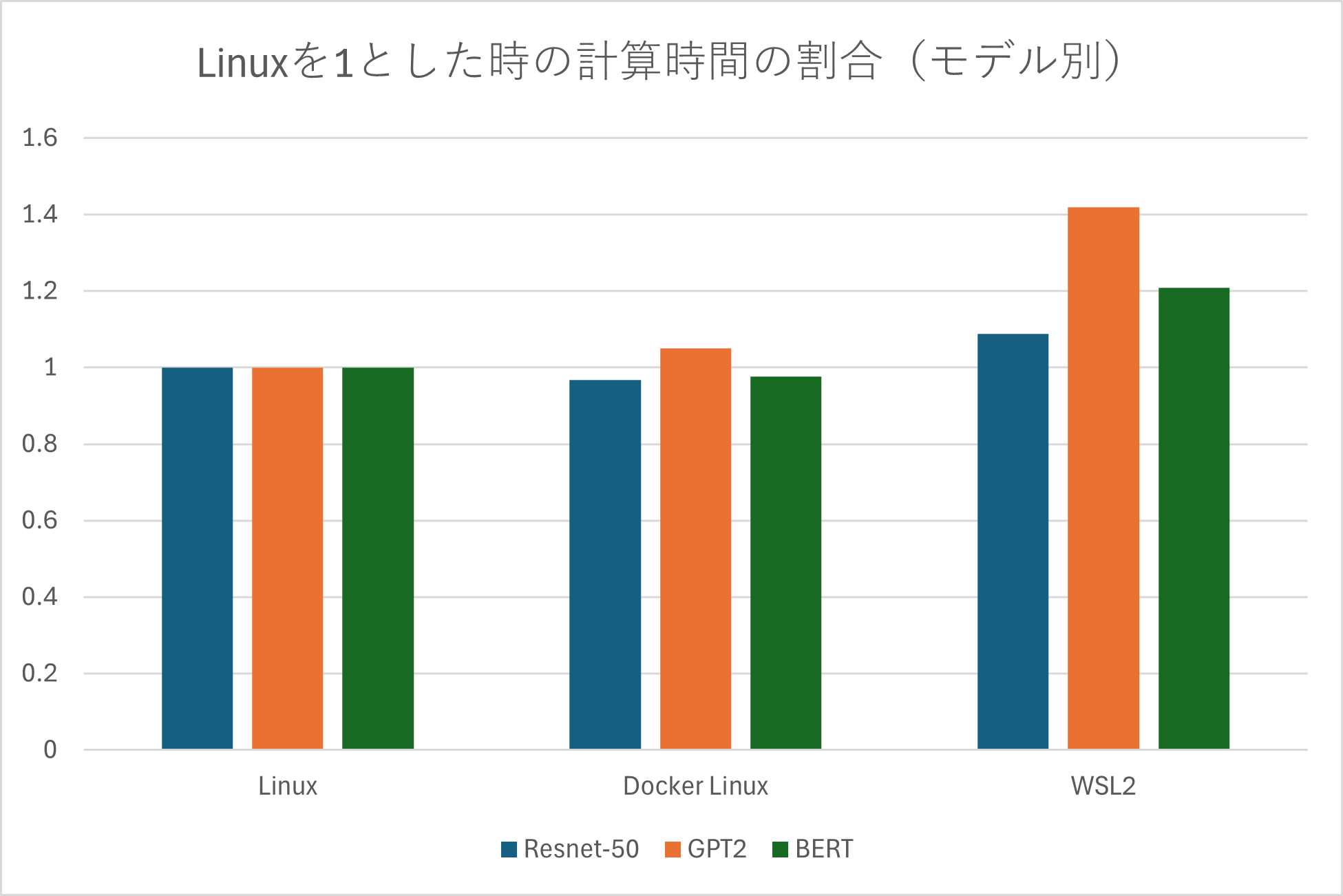
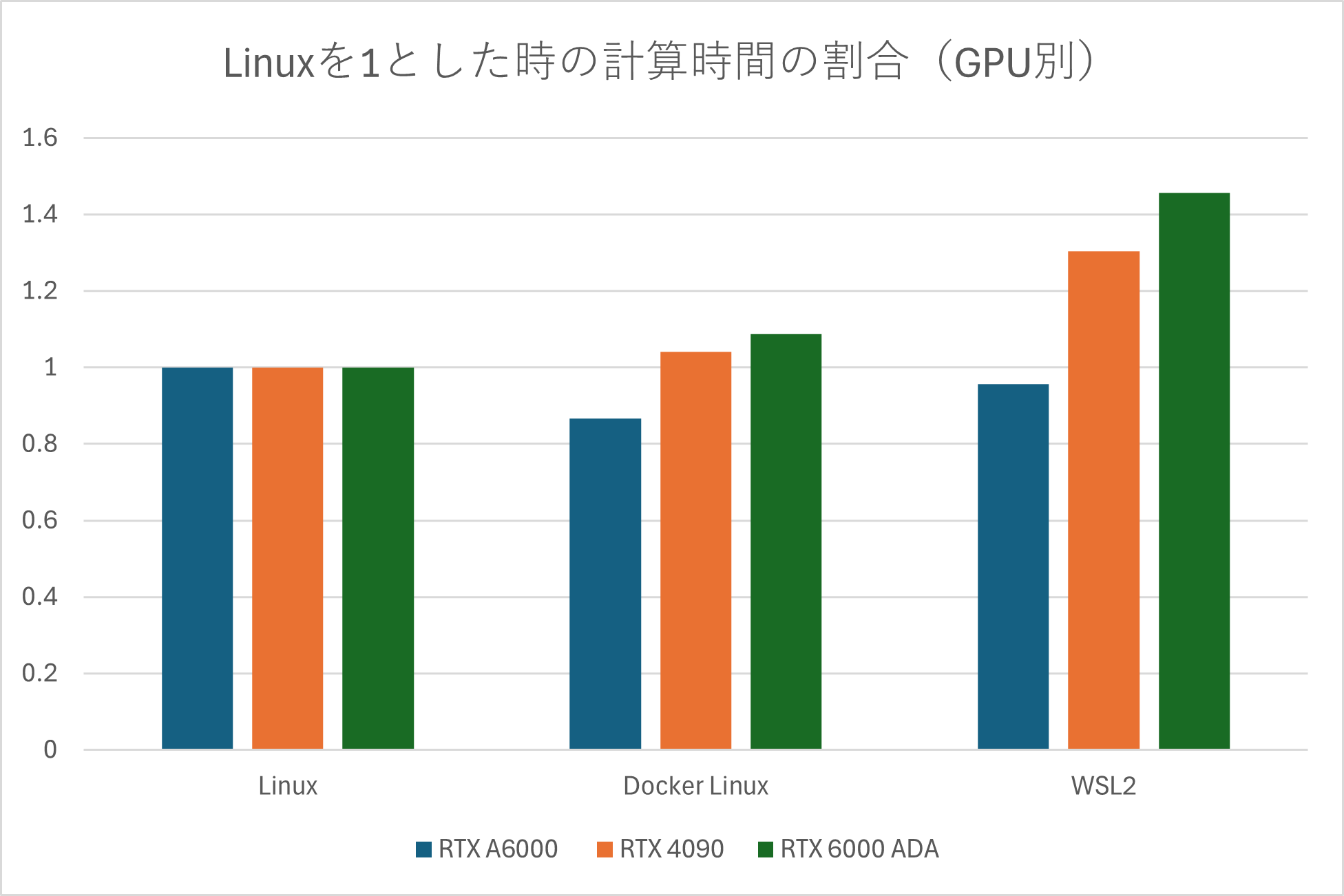
OSインストール環境の違いによる計算時間の割合
| Linuxを1とした時の計算時間の割合 (モデル別) | Linuxを1とした時の計算時間の割合 (GPU別) |
 |
 |
まとめ
検証の結果、ネイティブLinux環境の処理時間が最も速く、次いでDocker環境、Windows WSL2上の順となりました。

ただし、一部のDocker環境においては、ネイティブLinuxに環境よりも計算時間が短い場合があることも確認しています。ネイティブLinux環境はハードウェアへの直接アクセスにより最高のパフォーマンスが得られますが、Docker環境でもAI処理におけるオーバーヘッドの影響はほぼ無いと言えます。
一方、WSL2はWindowsで作業する上での利便性は高いものの、平均してネイティブ環境よりも計算時間が20%程度長いことを確認しました。これは、オーバーヘッドの影響によるものと考えられます。
今回はおもにOSインストール環境に主眼を置いて比較しましたが、GPUや他のハードウェア条件等によってもAI処理のパフォーマンスは変動します。今回の記事がワークステーションのスペックや、実行環境の検討にあたり参考になりましたら幸いです。
|
AIモデル開発用ワークステーションのご相談はお気軽に! 研究用・産業用PCの製作・販売サービス TEGSYS – テグシス
|





