もし、LLMに太宰治の『走れメロス』を要約させたらGPU構成ごとのパフォーマンスはどうなるのか?

はじめに
LLM (大規模言語モデル) の性能や信頼性を確認するにあたり、いくつかの定番テストが存在します。LLMに問題を解かせたりプログラムを制止させたりなど、数ある手法のひとつに「文章の要約」があります。
本記事では、
もし、LLMに太宰治の『走れメロス』を要約させたらGPU構成ごとのパフォーマンスはどうなるのか?また、どのような回答が得られるのか
という比較検証の結果をまとめます。

検証環境と条件
今回の検証で使用した環境は以下の通りです。
ハードウェア
| 検証用ハードウェア環境 | GPUの種類と数 | VRAM容量 |
| 構成1 | NVIDIA RTX 6000Ada ×1枚 | VRAM 48GB |
| 構成2 | NVIDIA RTX 4500Ada ×2枚 | VRAM 合計48GB (24GB×2) |
| 構成3 | NVIDIA RTX 6000Ada ×2枚 | VRAM 96GB |
ソフトウェア
Llama 3.3 70B + Ollama + Dify
・量子化設定:q2_K:26GB/ 通常モデル:43GB
※6000Ada x2枚のみ→q8_0:75GB /FP16:141GB
・デフォルト設定 (追加データなし)
▶ソフトウェア情報
|
◆Llmaとは ◆Ollamaとは ◆Difyとは |
検証における条件
LLMの挙動をそのまま確認するため、事前のファインチューニングや追加データの学習は一切行わず、プリセットのままで実験を行いました。
仮説
今回、メインで検証を行うGPUは、構成1 (RTX 6000 Ada ×1枚)と構成2 (RTX 4500 Ada ×2枚)の構成です。
どちらもVRAMの合計容量は同じですが、GPUの処理能力 (CUDAコアやメモリ速度) ではRTX 6000 Adaの方が優位です。
しかし、構成2 (RTX 4500 Ada ×2枚)はGPU ×2枚での並列処理により、構成1 (RTX 6000 Ada ×1枚)に匹敵する処理能力を発揮できるのではないかと想定しました。
また、構成2 (RTX 4500 Ada ×2枚)を上回る処理能力になることを期待して、構成3 (RTX 6000 Ada×2枚)でも検証を行いました。
検証結果
要約速度について
ハードウェア環境 構成1~構成3それぞれでの要約速度は、以下の結果となりました。
| ハードウェア構成 | 500字要約 (秒) | 1000字要約 (秒) |
| 構成1: NVIDIA RTX 6000Ada ×1枚 VRAM 48GB |
q2_K:11.18 / 43GB:53.02 | q2_K:22.69 / 43GB:51.67 |
| 構成2: NVIDIA RTX 4500Ada ×2枚 VRAM 合計48GB (24GB×2) |
q2_K:29.02 / 43GB:66.77 | q2_K:93.00 / 43GB:80.55 |
| 構成3: NVIDIA RTX 6000Ada ×2枚 VRAM 96GB |
q2_K:13.98 / 43GB:38.20 / 75GB:99.54 / 141GB:測定不能 | q2_K:40.75 / 43GB:44.23 / 75GB:87.19 / 141GB:測定不能 |
VRAM容量について
VRAM容量が増えることで、より大きなモデルや高精度な量子化を扱うことが可能になることがわかりました。
しかし、VRAMの増加が推論速度に関与することはなく、あくまで扱うことができるモデルが増えるだけである点には注意が必要です。
| ハードウェア構成 | 結果 |
| 構成1: NVIDIA RTX 6000Ada ×1枚 VRAM 48GB |
43GBモデルまで推論は可能。ただし、より大きなモデル (75GB以上) ではメモリ不足。 |
| 構成2: NVIDIA RTX 4500Ada ×2枚 VRAM 合計48GB (24GB×2) |
6000Ada×1枚と同じく43GBモデルまで推論が可能 |
| 構成3: NVIDIA RTX 6000Ada ×2枚 VRAM 96GB |
75GBモデルが動作。ただし、141GBモデルで推論を行うと搭載されたVRAM以上の容量分はCPUで処理が行われる用になるため、いつまで経っても推論が終わらない状態になってしまう。 |
推論速度について
構成1 (RTX 6000 Ada ×1枚) と構成3 (RTX 6000 Ada×2枚) の構成では、推論時間にそれほど大きな差は出ませんでした。しかし、構成2 (RTX 4500 Ada ×2枚) では、構成1 (RTX 6000 Ada ×1枚) と比較して、推論時間が大幅に増加しました。
構成1 (RTX 6000 Ada ×1枚) と構成3 (RTX 6000 Ada×2枚) で大きな差が出なかったのは、43GBモデルを推論させた際、2枚搭載したRTX 6000 Adaのうち、1枚のみで推論を完了させていたためです。つまり、デフォルト状態ではGPU処理の並列化が行われていないということになります。
また、構成2 (RTX 4500 Ada ×2枚) でも構成1 (RTX 6000 Ada ×1枚) と比較して推論速度が向上しなかったことから、GPUを増やしても、並列処理が行われない限り推論速度は向上しないことを確認しました。
推論速度を決定づけた要因
推論速度を決定づけた要因は、GPU自体の処理能力であると考えられます。RTX 6000 AdaとRTX 4500 Adaを比較すると、VRAMの搭載量だけでなく、CUDAコア数や単精度演算性能などの面でRTX 6000 Adaの方が2倍以上の性能を持ちます。この性能差は実際の推論時間にも顕著に表れており、GPUの数よりも個々のGPUの計算能力が推論速度に大きく影響することが確認できました。
なお、NVLinkを活用することで、VRAMを仮想的に統合したり、複数のGPUを連携させることが可能になりますが、今回の検証ではNVLinkを利用したメモリ共有や並列推論を設定しませんでした。この点が、GPUの増設による推論速度向上が見られなかった一因であるとも考えられます。
今後、NVLinkの活用や並列処理の最適化を行うことで、複数GPU構成の効果を引き出せるかどうかも検証する価値がありそうです。
Llamaによる要約の内容について
前述の通り、今回の比較検証ではLLMに太宰治の「走れメロス」を要約させました。
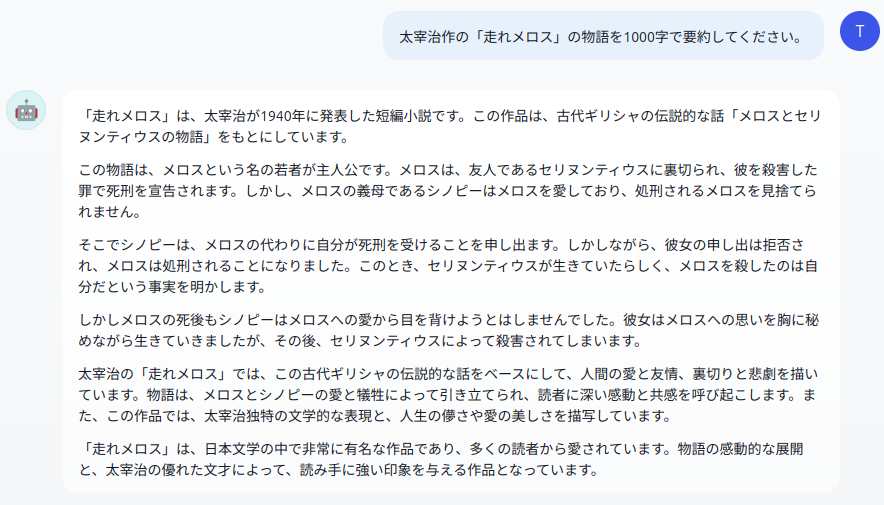
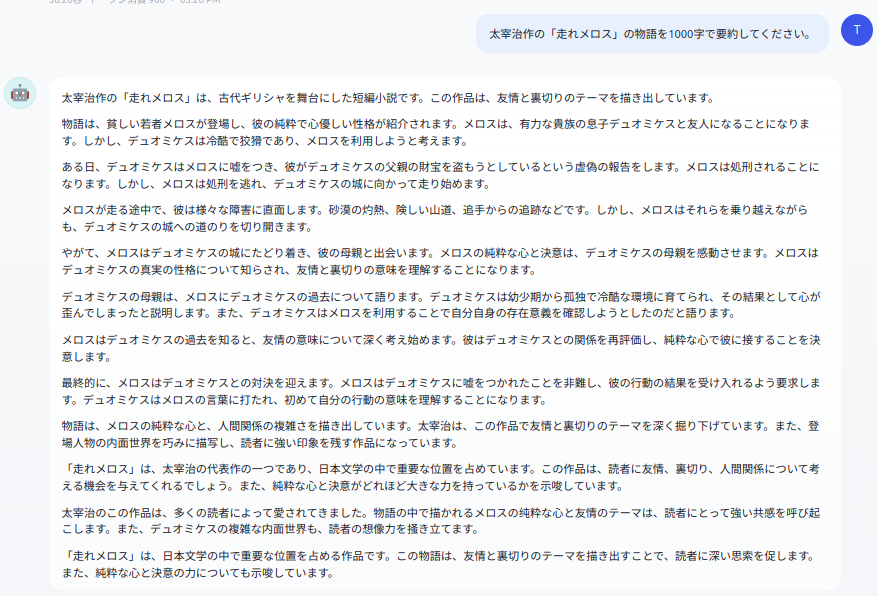
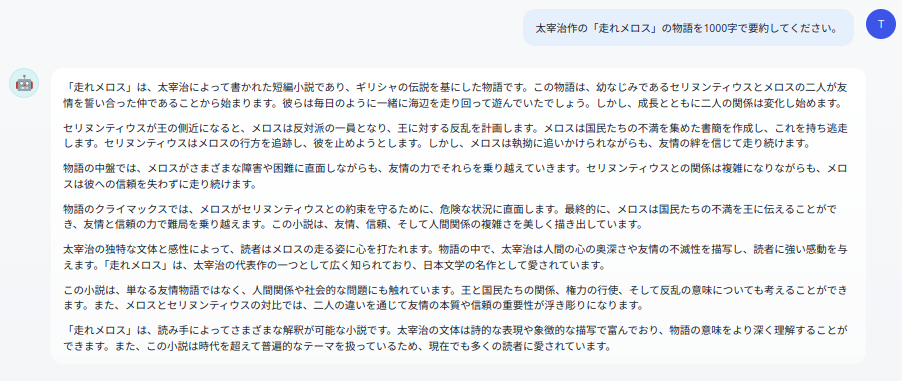
実際の要約結果では、メロスが友人のセリヌンティウスに裏切られたり、メロスが王への反乱を企てていたりと、原作とはまったく異なるストーリーになっていました。
しかし、どんな理由であれ「メロスは走っている」という部分は共通しています。
要約結果の一部抜粋①
“「走れメロス」は、太宰治によって書かれた短編小説であり、ギリシャの伝説を基にした物語です。この物商は、幼なじみであるセリヌンティウスとメロスの二人が友情を誓い合った仲であることから始まります。彼らは毎日のように一緒に海辺を走り回って遊んでいたでしょう。しかし、成長とともに二人の関係は変化し始めます。
セリヌンティウスが王の側近になると、メロスは反対派の一員となり、王に対する反乱を計画します。メロスは国民たちの不満を集めた書簡を作成し、これを持ち逃走します。セリヌンティウスはメロスの行方を追跡し、彼を止めようとします。しかし、メロスは執拗に追いかけられながらも、友情の絆を結じて走り続けます。”
要約結果の一部抜粋②
“太宰治作の「走れメロス」は、古代ギリシャを舞台にした短編小説です。この作品は、友情と裏切りのテーマを描き出しています。
物語は、貧しい若者メロスが登場し、彼の純粋で心優しい性格が紹介されます。メロスは、有力な貴族の息子デュオミケスと友人になることになります。しかし、デュオミケスは冷酷でであり、メロスを利用しようと考えます。
ある日、デュオミケスはメロスに嘘をつき、彼がデュオミケスの父親の財宝を盗もうとしているという虚偽の報告をします。メロスは処刑されることになります。しかし、メロスは処刑を逃れ、デュオミケスの城に向かって走り始めます。”
▼要約結果の全文は下記画像をクリックしてご覧ください
 |
 |
 |
この原因は、Llamaが元データとしているコーパス (LLMモデルの訓練に使用される大規模なテキストデータの集合) にあると考えられます。要約を行う際、モデルが参照する情報は学習済みデータに依存するため、学習データ以外の情報は「補完」「推測」されてしまう傾向にあります。
また、著作権の関係から本記事に掲載することはできませんが、海外作品の要約では非常に精度の高い結果が出力されましたので、デフォルト状態のLlamaは日本文学に弱いと言えそうです。
※日本文学でも精度の高い要約を行うには、追加データを投入して事前学習させる方法があります。今回はあえて「そのままの状態」で試したため、Llamaの“独自解釈”が展開されることになりました。
考察:VRAMと推論性能の関係
今回の結果から、LLM推論とVRAM容量に関しては以下のことが言えそうです。
[1]VRAMが増えれば速度が上がるとは限らない
VRAMやGPUを増加・増設することで、大きなモデルを動かすことが可能となりますが、必ずしも速度向上につながるわけではありません。
特に、構成2 (RTX 4500 Ada ×2枚)にて小容量のLLMモデルを推論させた場合、単体の構成1 (RTX 6000 Ada ×1枚) に勝るとは限りません。
つまり、推論速度はGPU本体の計算能力に依存すると考えられます。
[2]追加学習なしのLLMは予測不能な要約をする
一般的にLLMを正確に活用するには、事前に適切なデータセットを追加し、学習させることが重要です。
Llamaの標準モデルは、一般的な情報をベースに要約しますが、文脈を正しく理解するとは限りません。
今回の検証のように、小説を要約させるとストーリーの根幹がズレた要約を生成する可能性があります。
まとめ
今回の検証についてのまとめは以下の通りです。
[1]LLMにおけるVRAMは推論できる規模に関わる。
[2]推論速度はGPU性能によって左右される要素が多い。→複数枚GPUを搭載する際はNVLinkの導入も選択肢に入りそうです。
[3]追加データなしの状態で推論を行うと、意図しない回答をすることがある。

今後の検証では、
-
- Llmaでの生成結果に対する精度向上
- 事前訓練済みモデルを再訓練して、特定のタスクに適応させた場合の精度向上
- VRAMのさらに大容量な構成でのテスト
- GeForce系GPUとの比較
- NVLinkでの各種設定をした場合の速度比較
などを予定しています。
関連情報
自然言語処理に関連するPC提案事例
|
|
|




AIモデルに関連する技術記事
- OSインストール環境の違いによるAIの実行Performance比較 (Linux、Docker、WSL2)
- 主要なAIモデルにおける RTX シリーズ GPUのパフォーマンス比較検証
- 主要なAIモデルにおける RTX シリーズ GPUのパフォーマンス比較検証②
|
LLM向けワークステーション選びのご相談はお気軽に! 研究用・産業用PCの製作・販売サービス TEGSYS – テグシス
|





